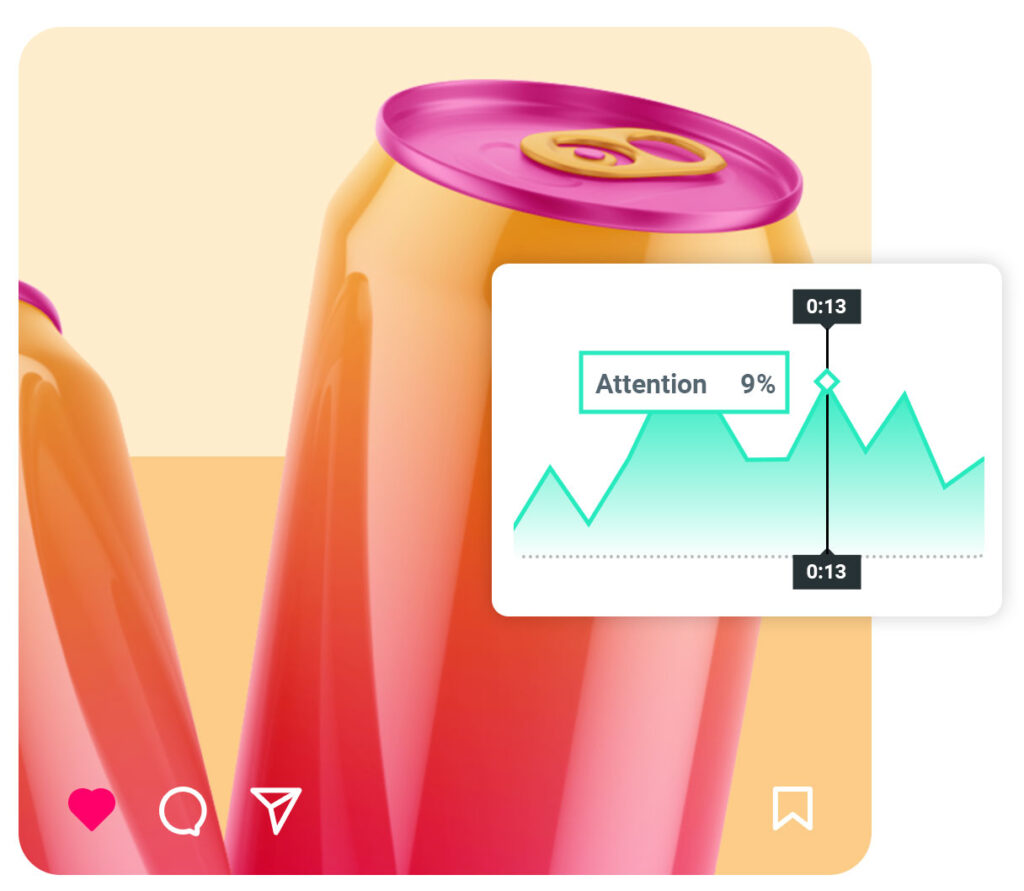






Our AI is one of the highest performing in the world for unconstrained, real-life situations and light enough to run continuously on most mobile devices
Our models are trained on proprietary visual data that has been obtained in accordance with the highest legal, privacy and ethical standards
Our models have minimal bias across user dimensions such as skin tone, gender and age


